Energy signature#
A Bayesian workflow for M&V#
This tutorial applies the principles of Bayesian data analysis to a Measurement and Verification (M&V) problem. In a nutshell, M&V aims at reliably assessing the energy savings that were actually gained from energy conservation measures (ECM). One of the main M&V workflows, formalised by the IPMVP, is the “reporting period basis”, or “avoided consumption” method:
a numerical model is trained during a baseline observation period (before ECMs are applied);
the trained model is used to predict energy consumption during the reporting period (after energy conservation measures);
predictions are compared with the measured consumption of the reporting period, in order to estimate adjusted energy savings
This method therefore requires data to be recorded before and after implementation of the ECM, for a sufficiently long time. Fig. 18 shows the main steps of this method, when following a Bayesian approach. We assume that the measurement boundaries have been defined and that data have been recorded during the baseline and reporting period respectively.
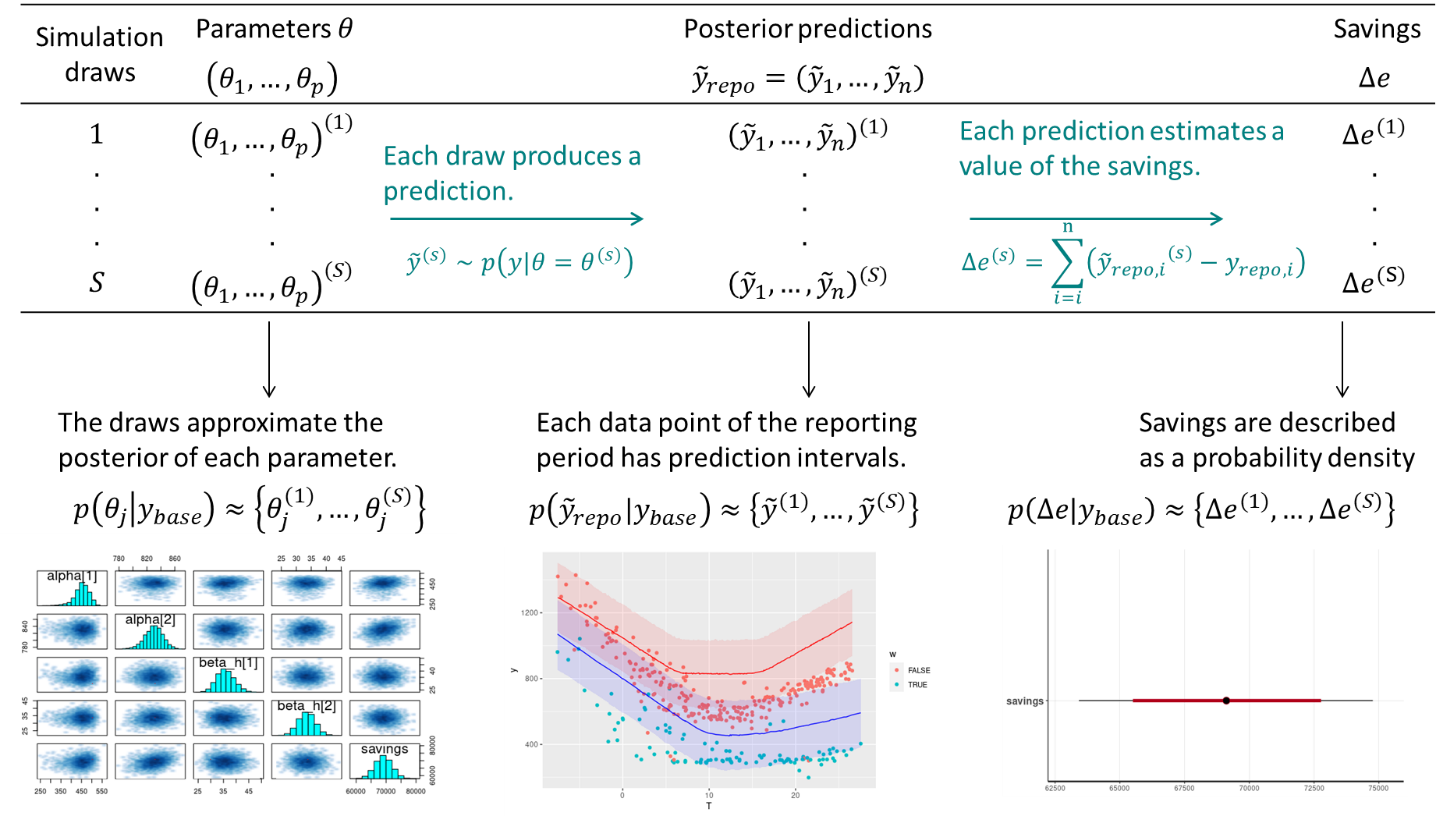
Fig. 18 Estimation of savings with uncertainty in an avoided consumption workflow. The step of model validation is not displayed#
As with standard approaches, choose a model structure to describe the data with, and formulate it as a likelihood function. Formulate eventual “expert knowledge” assumptions in the form of prior probability distributions.
Run a MCMC (or other) algorithm to obtain a set of samples \(\left(\theta^{(1)},...,\theta^{(S)}\right)\) which approximates the posterior distribution of parameters conditioned on the baseline data \(p(\theta|y_\mathit{base})\). Validate the inference by checking convergence diagnostics: \(\hat{R}\), ESS, etc.
Validate the model by computing its predictions during the baseline period \(p(\tilde{y}_\mathit{base}|y_\mathit{base})\). This can be done by taking all (or a representative set of) samples individually, and running a model simulation \(\tilde{y}_\mathit{base}^{(s)} \sim p(y_\mathit{base}|\theta=\theta^{(s)})\) for each. This set of simulations generates the posterior predictive distribution of the baseline period, from which any statistic can be derived (mean, median, prediction intervals for any quantile, etc.). The measures of model validation (\(R^2\), net determination bias, t-statistic…) can then be computed either from the mean, or from all samples in order to obtain their own probability densities.
Compute the reporting period predictions in the same discrete way: each sample \(\theta^{(s)}\) generates a profile \(\tilde{y}_\mathit{repo}^{(s)} \sim p(y_\mathit{repo}|\theta=\theta^{(s)})\), and this set of simulations generates the posterior predictive distribution of the reporting period.
Since each reporting period prediction \(\tilde{y}_\mathit{repo}^{(s)}\) can be compared with the measured reporting period consumption \(y_\mathit{repo}\), we can obtain \(S\) values for the energy savings, which distribution approximate the posterior probability of savings.
Energy signature and change-point models#
Some systems are dependent on a variable, but only above or below a certain value. For example, cooling energy use may be proportional to ambient temperature, yet only above a certain threshold. When ambient temperature decreases to below the threshold, the cooling energy use does not continue to decrease, because the fan energy remains constant. In cases like these, simple regression can be improved by using a change-point linear regression. Change point models often have a better fit than a simple regression, especially when modeling energy usage for a facility.
A simple energy signature of a building decomposes the total energy consumption \(y\) (or power, depending on which measurement is available) into three terms: heating, cooling, and other uses. Heating and cooling are then assumed to be linearly dependent on the outdoor air temperature \(x\), and only turned on conditionally on two threshold temperatures \(\tau_1\) and \(\tau_2\), respectively.
Where the \(1\) and \(2\) subscripts indicate heating and cooling modes. The \(+\) superscript indicates that a term is only applied if above zero. This equation means that we expect the energy use \(y\) to be a normal distribution centered around a change-point model, with a constant standard deviation \(\sigma\).
Data points should be averaged over long enough (at least daily) sampling times, so that the steady-state assumption formulated above can hold. \(\alpha\) is the average baseline consumption during each sampling period, of all energy uses besides heating and cooling. Heating is turned on if the outdoor air temperature drops below a basis temperature \(\tau_1\), and the heating power \(\beta_1 \, \left(\tau_1 - x_n\right)\) increases linearly with the difference between the change point \(\tau_1\) and the outdoor air temperature \(x_n\). The same reasoning is used to formulate cooling above a \(\tau_2\) change point.
The appeal of the energy signature model is that the only data it requires are energy meter readings and outdoor air temperature, with a large time step size.
This model has 6 possible parameters: a constant term \(\alpha\), two slopes \(\beta\), two change points \(\tau\) and the error scale \(\sigma\). It is not an ordinary linear regression models: there is no analytical way to formulate the prediction uncertainty while accounting for the uncertainty of the change point estimates.
IPMVP option C example with Stan#
Data#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import arviz as az
from cmdstanpy import CmdStanModel
The data used in this example is the hourly electricity consumption and outdoor air temperature data for a commercial building in Richmond, USA. Three file are available: building6pre.csv, building6during.csv and building6post.csv, respectively before and after some energy conservation measure has been applied.
Each file can be downloaded from this folder.
The following block loads the hourly data, resamples it on daily time steps, and removes week ends.
def load_and_resample_data(file):
df = pd.read_csv(file)
df.set_index(pd.to_datetime(df["Date"]), inplace = True)
df.drop("Date", axis=1, inplace=True)
df['OAT'] = (df['OAT']-32)/1.8
df['dayofweek'] = df.index.dayofweek
df['weekend'] = (df['dayofweek'] == 5) | (df['dayofweek'] == 6)
df = df.groupby(df.index.date).mean()
return df
df1 = load_and_resample_data('data/building6pre.csv')
df2 = load_and_resample_data('data/building6during.csv')
df3 = load_and_resample_data('data/building6post.csv')
Averaging the data over daily time steps should allow to overlook the dependence between consecutive measurements. In turn, this allows using a model which will be much simpler than time series models, but will only be capable of low frequency predictions.
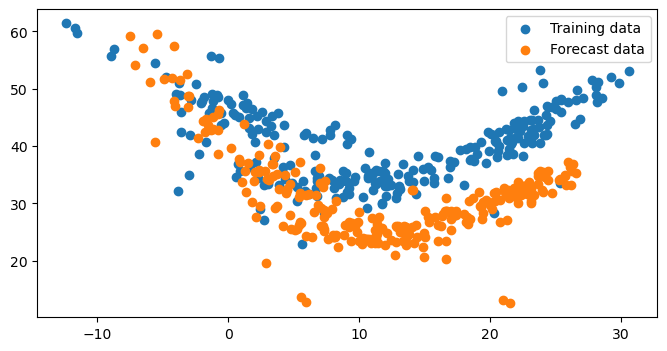
The next block plot the daily average power consumption (kW) versus the outdoor air temperature (°C) for both datasets: the year used for training (baseline period) and the year used for forecasting (reporting period).
#weekend = (df1['dayofweek'] == 5) | (df1['dayofweek'] == 6)
df_train = df1.loc[df1['weekend']==False]
df_test = df3.loc[df3['weekend']==False]
fig, ax = plt.subplots(figsize=(8, 4))
ax.scatter(df_train['OAT'], df_train['Building 6 kW'], label='Training data')
ax.scatter(df_test['OAT'], df_test['Building 6 kW'], label='Forecast data')
ax.legend()
<matplotlib.legend.Legend at 0x7fe4d2a93b60>
Model specification#
After looking at the data, we can suggest using a change-point model which will include the effects of heating and cooling separately, like we defined in Equation (24) above.
The complete Stan code for the energy signature model is written into a separate file, loaded by CmdStanPy:
model = CmdStanModel(stan_file='models/changepoint_101.stan')
09:54:02 - cmdstanpy - INFO - compiling stan file /tmp/tmprpop4u76/tmpa9rc_q37.stan to exe file /media/simon/donnees/Boulot/tutos et sites/buildingenergygeeks/models/changepoint_101
10:00:40 - cmdstanpy - INFO - compiled model executable: /media/simon/donnees/Boulot/tutos et sites/buildingenergygeeks/models/changepoint_101
I called it “changepoint_101” because it may have a slope on the low temperatures side (1), then a section of temperature-independent energy use (0), then a slope on the high temperatures side (1).
The blocks of the code are separated here to facilitate their description.
First, the data declaration block is more complex than in the previous linear regression example for two reasons:
Two datasets are being passed to the Stan model: training data, and forecasting data. Each comes with a variable for the number of data entries \(N\), input variables \(x\) and output \(y\).
Parameter priors are passed as data into the model. This is so that their values can be modified in the main code before refitting, instead of being defined inside the Stan model, which would require recompiling every time we want to try new prior values.
data {
// This block declares all data which will be passed to the Stan model.
// Training period
int<lower=0> N; // number of data items
vector[N] x; // outdoor temperature
vector[N] y; // outcome energy vector
// Post period
int<lower=0> N_post; // number of data items
vector[N_post] x_post; // outdoor temperature
vector[N_post] y_post; // outcome energy vector
// Priors
array[2] real alpha_prior;
array[2] real beta1_prior;
array[2] real beta2_prior;
array[2] real tau1_prior;
array[2] real tau2_prior;
}
The parameter block declares the six parameters of the model as separate real-valued variables:
parameters {
// This block declares the parameters of the model.
real alpha; // baseline consumption
real beta1; // slope for heating
real beta2; // slope for cooling
real tau1; // low temperature break point
real tau2; // high temperature break point
real<lower=0> sigma; // error scale
}
The model itself is below. First, it declares the prior distribution of each parameter as a normal distribution, with a mean and standard deviation taken from the declared data. It includes the declaration of prior distributions, because these variables have been declared as data passed to the Stan model.
Then, the observational model is the energy signature equation (24).
model {
// Assigning prior distributions on some parameters
alpha ~ normal(alpha_prior[1], alpha_prior[2]);
beta1 ~ normal(beta1_prior[1], beta1_prior[2]);
beta2 ~ normal(beta2_prior[1], beta2_prior[2]);
tau1 ~ normal(tau1_prior[1], tau1_prior[2]);
tau2 ~ normal(tau2_prior[1], tau2_prior[2]);
// Observational model
for (n in 1:N) {
y[n] ~ normal(alpha + beta1 * fmax(tau1-x[n], 0) + beta2 * fmax(x[n]-tau2, 0), sigma);
}
}
Finally, the block for generated quantities is quite larger than in the previous tutorial. This block handles the calculation of some posterior variables we want to study after fitting:
Energy use predictions by the model during the training period
y_hatand during the reporting periody_hat_postLog-likelihood
log_lik, which is useful to save if we want to compare several fitted models.Energy savings, which are the total difference between the forecasts and the measured reporting period energy use.
generated quantities {
// This block is for posterior predictions. It is not part of model training
array[N] real log_lik;
array[N] real y_hat;
array[N_post] real y_hat_post;
real savings = 0;
for (n in 1:N) {
y_hat[n] = normal_rng(alpha + beta1 * fmax(tau1-x[n], 0) + beta2 * fmax(x[n]-tau2, 0), sigma);
log_lik[n] = normal_lpdf(y[n] | alpha + beta1 * fmax(tau1-x[n], 0) + beta2 * fmax(x[n]-tau2, 0), sigma);
}
for (n in 1:N_post) {
y_hat_post[n] = normal_rng(alpha + beta1 * fmax(tau1-x_post[n], 0) + beta2 * fmax(x_post[n]-tau2, 0), sigma);
savings += y_hat_post[n] - y_post[n];
}
}
Note that predictions are calculated by drawing from a Normal distribution with the \(\sigma\) error of each sample. Therefore, we will obtain a full description of the prediction intervals.
The next step is to create a list called model_data, which maps our data to each appropriate variable into the Stan model. Then the sample() command samples from the posterior conditioned on this data.
model_data = {
"N": len(df_train),
"x": df_train['OAT'],
"y": df_train['Building 6 kW'],
"N_post": len(df_test),
"x_post": df_test['OAT'],
"y_post": df_test['Building 6 kW'],
"alpha_prior": [35, 5], # baseline consumption at intermediate temperatures
"beta1_prior": [2, 1], # low temperature slope
"beta2_prior": [2, 1], # high temperature slope
"tau1_prior": [8, 3], # low temperature break point
"tau2_prior": [15, 3], # high temperature break point
}
fit = model.sample(data=model_data, show_progress=False)
10:00:40 - cmdstanpy - INFO - CmdStan start processing
10:00:40 - cmdstanpy - INFO - Chain [1] start processing
10:00:40 - cmdstanpy - INFO - Chain [2] start processing
10:00:40 - cmdstanpy - INFO - Chain [3] start processing
10:00:40 - cmdstanpy - INFO - Chain [4] start processing
10:00:52 - cmdstanpy - INFO - Chain [1] done processing
10:00:54 - cmdstanpy - INFO - Chain [4] done processing
10:00:54 - cmdstanpy - INFO - Chain [3] done processing
10:00:56 - cmdstanpy - INFO - Chain [2] done processing
The diagnose() method looks for potential problems which indicate that the sample may not be a representative sample from the posterior. If some of the metrics are not satisfactory, Stan’s documentation has a page suggesting how to address these warnings..
print(fit.diagnose())
Checking sampler transitions treedepth.
Treedepth satisfactory for all transitions.
Checking sampler transitions for divergences.
No divergent transitions found.
Checking E-BFMI - sampler transitions HMC potential energy.
E-BFMI satisfactory.
Rank-normalized split effective sample size satisfactory for all parameters.
Rank-normalized split R-hat values satisfactory for all parameters.
Processing complete, no problems detected.
If no problems are detected, we can take a look at some metrics from the posterior distributions of model parameters:
fs = fit.summary(percentiles=(5, 50, 95))
fs.loc[['alpha', 'beta1', 'beta2', 'tau1', 'tau2', 'sigma', 'lp__']]
| Mean | MCSE | StdDev | MAD | 5% | 50% | 95% | ESS_bulk | ESS_tail | R_hat | |
|---|---|---|---|---|---|---|---|---|---|---|
| alpha | 34.53650 | 0.011301 | 0.491664 | 0.476137 | 33.706700 | 34.55990 | 35.29330 | 1992.97 | 1810.27 | 1.000390 |
| beta1 | 1.38307 | 0.002249 | 0.113015 | 0.112633 | 1.197940 | 1.38221 | 1.56993 | 2523.00 | 2563.90 | 1.002240 |
| beta2 | 1.19319 | 0.002822 | 0.128784 | 0.128193 | 0.987596 | 1.18844 | 1.41407 | 2125.05 | 2196.14 | 1.000900 |
| tau1 | 6.58969 | 0.019484 | 0.774214 | 0.762909 | 5.458700 | 6.53799 | 7.95173 | 1713.55 | 1949.51 | 1.001010 |
| tau2 | 15.59330 | 0.023449 | 0.958623 | 0.956944 | 13.957300 | 15.64830 | 17.05940 | 1716.51 | 2244.32 | 1.000610 |
| sigma | 4.02920 | 0.003017 | 0.180645 | 0.179157 | 3.735960 | 4.02018 | 4.34370 | 3660.74 | 2451.36 | 0.999873 |
| lp__ | -490.92400 | 0.042934 | 1.751260 | 1.608620 | -494.172000 | -490.57800 | -488.70400 | 1682.00 | 2611.63 | 1.000350 |
Since all convergence diagnostics are fine, we can save results into an ArviZ InferenceData object which will facilitate further analysis.
# The sampler output is saved into an xarray
res_xr = fit.draws_xr()
# Then the xarray is converted into an ArviZ InferenceData object
idata = az.from_cmdstanpy(
posterior = fit,
posterior_predictive="y_hat",
observed_data={"y": df1['Building 6 kW'].values},
constant_data={"x": df1[['OAT']].values},
log_likelihood="log_lik",
dims={
"y_hat": ["observations"],
"log_lik": ["observations"],
"y": ["observations"],
"y_hat_post": ["forecast"]
},
)
Posterior predictions#
Our main goal here is to compare the energy use measured during the reporting period \(y_\mathit{repo}\) with the predictions of the model trained on the baseline period. Since it is a probabilistic model, its outcome is actually a probability distribution \(p\left(\hat{y}_\mathit{repo}|x_\mathit{repo}, x_\mathit{base}, y_\mathit{base}\right)\), based on the observed values of the model inputs \(x\) during the baseline and reporting periods, and on the observed energy use during the baseline period \(y_\mathit{base}\).
This posterior predictive distribution \(p\left(\hat{y}_\mathit{repo}|...\right)\) is already directly available, because a value of \(\hat{y}_\mathit{repo}\) (for each time step) was directly calculated by the Stan model for each sample \(\theta^{(m)}\) (see Stan user’s guide for more details).
In the generated quantities block of the Stan code, we defined two posterior predictive quantities:
y_hatare predictions by the trained model within the baseline period. All samples ofy_hatform the posterior predictive distribution within the training set: \(p\left(\hat{y}_\mathit{base}|x_\mathit{base}, y_\mathit{base}\right)\)y_hat_postare predictions over the “post” dataset. All samples form the posterior predictive distribution of the reporting period: \(p\left(\hat{y}_\mathit{repo}|x_\mathit{repo}, x_\mathit{base}, y_\mathit{base}\right)\)
The following block displays both, compared to their respective dataset.
y_hat = idata.posterior_predictive["y_hat"]
y_hat_post = idata.posterior["y_hat_post"]
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
ax[0].scatter(df_train['OAT'], df_train['Building 6 kW'], label="data")
ax[0].scatter(df_train['OAT'], y_hat.mean(("chain", "draw")), s=1, c="C1", label="posterior mean")
az.plot_hdi(df_train['OAT'], y_hat, ax=ax[0])
ax[0].set_xlabel('Outdoor air temperature')
ax[0].set_ylabel('Building 6 kW')
ax[0].legend()
ax[1].scatter(df_test['OAT'], df_test['Building 6 kW'])
ax[1].scatter(df_test['OAT'], y_hat_post.mean(("chain", "draw")), s=1, c="C1")
az.plot_hdi(df_test['OAT'], y_hat_post, ax=ax[1])
ax[1].set_xlabel('Outdoor air temperature')
ax[1].set_ylabel('Building 6 kW')
Text(0, 0.5, 'Building 6 kW')
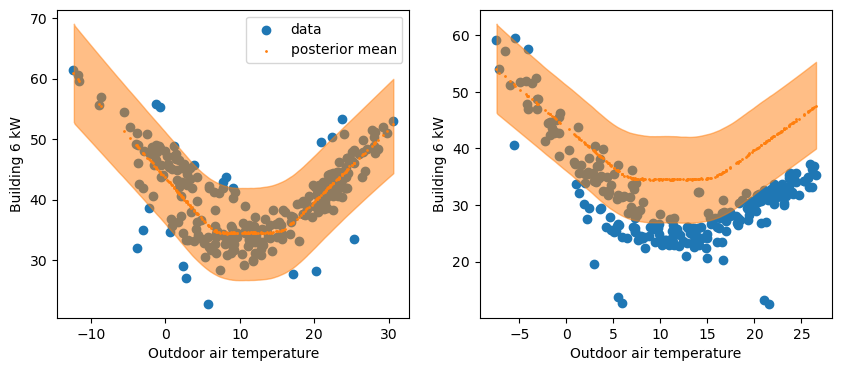
The left plot confirms a good fit between the training data and the predictions from the trained model. Most data points lie within the prediction intervals.
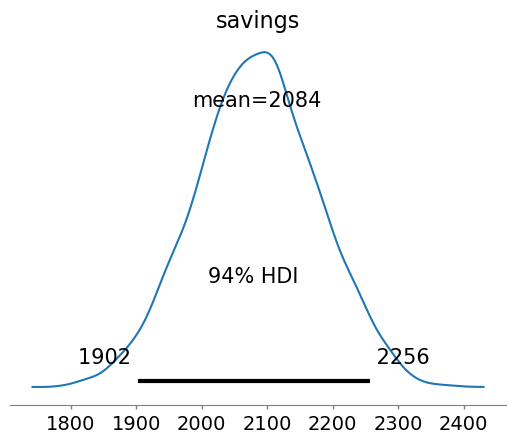
The right plot shows that the actual consumption during the reporting period is lower than predictions, which suggests that energy savings were made. The sum of the differences between predictions and consumption during this period are the total savings. They were formulated within the generated quantities of the Stan code, and we can therefore directly display their posterior distribution:
# in kW.day
az.plot_posterior(idata, var_names='savings')
<Axes: title={'center': 'savings'}>
An important validation step is to check for autocorrelation in the residuals of the fitted model, on the baseline data that was used for fitting. Autocorrelation is often a sign of insufficient model complexity, or that the form of the model error term has not been appropriately chosen. In case of strong remaining autocorrelation, inferences should be drawn with caution.
ArviZ has a built-in function to display the autocorrelation of the posterior traces, but we can also use it for a custom variable that is not contained in an InferenceData object.
resid = df_train['Building 6 kW'] - y_hat.mean(("chain", "draw"))
az.plot_autocorr(resid.values, max_lag=50)
<Axes: title={'center': 'x\n0'}>
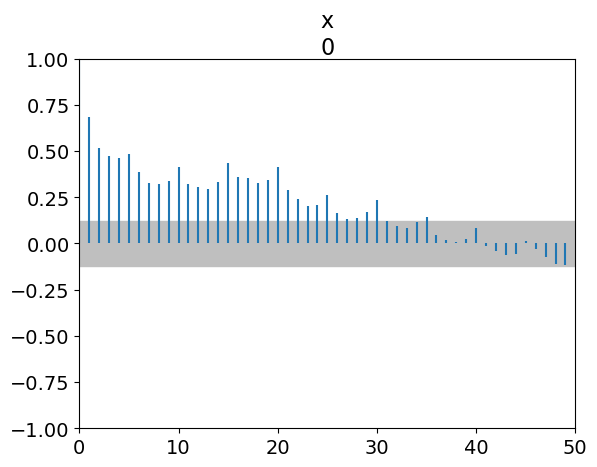
Every vertical line of this graph shows the correlation coefficient between the values of a series and its own values with a certain lag.
For
Lag=0, the ACF is 1. This is normal: a series is fully correlated with itself.As much as possible, we want all other ACF values below the dotted line, a threshold value which depends on the length of data.
For
Lag=1, the ACF is close to 0.7. This is the average correlation coefficient between residuals and their own previous value. As a consequence, the next lags have high ACF values as well.There is an increased ACF every 5 lags. Reminder: we removed weekends, therefore our dataset has 5 rows per week. This suggests that the data has a weekly pattern that our model doesn’t capture.
We can zoom in on the lag-1 autocorrelation by plotting residuals versus their own previous value:
fig, ax = plt.subplots(figsize=(8, 4))
ax.scatter(resid, resid.shift(1))
<matplotlib.collections.PathCollection at 0x7fe4d2101a90>
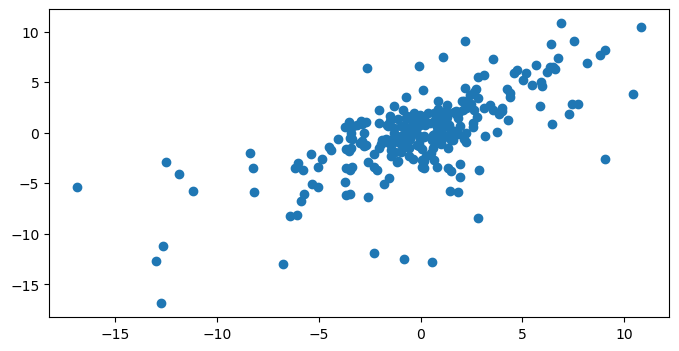
The autocorrelation graph suggests that our model doesn’t predict the variability of the data properly. We should therefore be very cautious when interpreting its inferences. This includes the uncertainty of the savings estimates.
In order to trust our inferences, we have two options:
Improve the model so that it better describes the building’s electricity use and its dependency on weather and occupancy. This means more model parameters, but the dataset may no longer bring enough information to identify them.
Modify the model to account for an additional uncertainty due to the autocorrelation. This means we will not “fix” the model, but let it aknowledge that it is missing something: inferences will be more “cautious” (more uncertain but more reliable).
In the next tutorial, we show how to do the second option.